Puntos clave
- La tabla de extracción de datos es el puente entre los estudios incluidos y el análisis o síntesis final: si está mal diseñada, la síntesis quedará incompleta o sesgada por más rigurosa que sea la búsqueda previa.
- Una plantilla efectiva combina cinco bloques: identificación del estudio, características de participantes, intervención, comparación y outcomes, y evaluación del riesgo de sesgo, adaptados al tipo de diseño del estudio.
- La doble extracción independiente con reconciliación posterior es el estándar metodológico recomendado por Cochrane y replicado por JBI; reduce errores aleatorios y elimina sesgos sistemáticos en la captura de datos.
- Los errores más frecuentes en extracción son no operacionalizar las variables antes de empezar, no pilotar la plantilla con tres a cinco estudios y no registrar los datos faltantes como dato en sí mismo.
- La elección de herramienta (Excel, Google Sheets, RevMan, Covidence, SynthIA, REDCap) depende del tamaño de la revisión, del número de revisores y de si el proceso requiere validación cruzada estructurada.
Qué es la tabla de extracción y por qué define la calidad de la revisión
En el ciclo de una revisión sistemática, la extracción de datos es la fase donde el equipo lee a fondo cada estudio incluido y captura de forma estructurada la información que después permitirá responder la pregunta de investigación. Es una fase que parece técnica pero que en realidad es la más cargada de decisiones metodológicas: qué variables capturar, con qué nivel de detalle, en qué unidad, qué hacer cuando el estudio reporta el dato de forma ambigua o cuando el dato falta.
Una tabla de extracción mal diseñada compromete todo lo que viene después. Si no se captura el tamaño muestral por brazo, el meta-análisis es imposible. Si no se registra la duración de la intervención, el análisis de subgrupos por dosis-respuesta no se puede hacer. Si no se anota el método de aleatorización, la evaluación del riesgo de sesgo queda en el aire. Y a diferencia de la búsqueda o el cribado, la extracción rara vez se rehace: el coste de volver a leer todos los estudios incluidos para capturar una variable olvidada es prohibitivo en proyectos con más de veinte a treinta estudios.
El principio fundamental: pre-especificar antes de extraer
PRISMA 2020 y el Cochrane Handbook coinciden en un principio simple: la plantilla de extracción se diseña, pilota y congela antes de empezar la extracción formal. Cualquier modificación durante el proceso debe registrarse y aplicarse retroactivamente a los estudios ya extraídos. Esta disciplina protege contra el sesgo de extracción selectiva, donde el revisor empieza a fijarse solo en los datos que confirman su hipótesis a medida que avanza la lectura.
La pre-especificación se concreta en el protocolo, idealmente registrado en PROSPERO antes del inicio formal de la revisión. La tabla de extracción y el manual de codificación son anexos del protocolo y se citan en el manuscrito final como evidencia de que el proceso fue estructurado desde el principio.
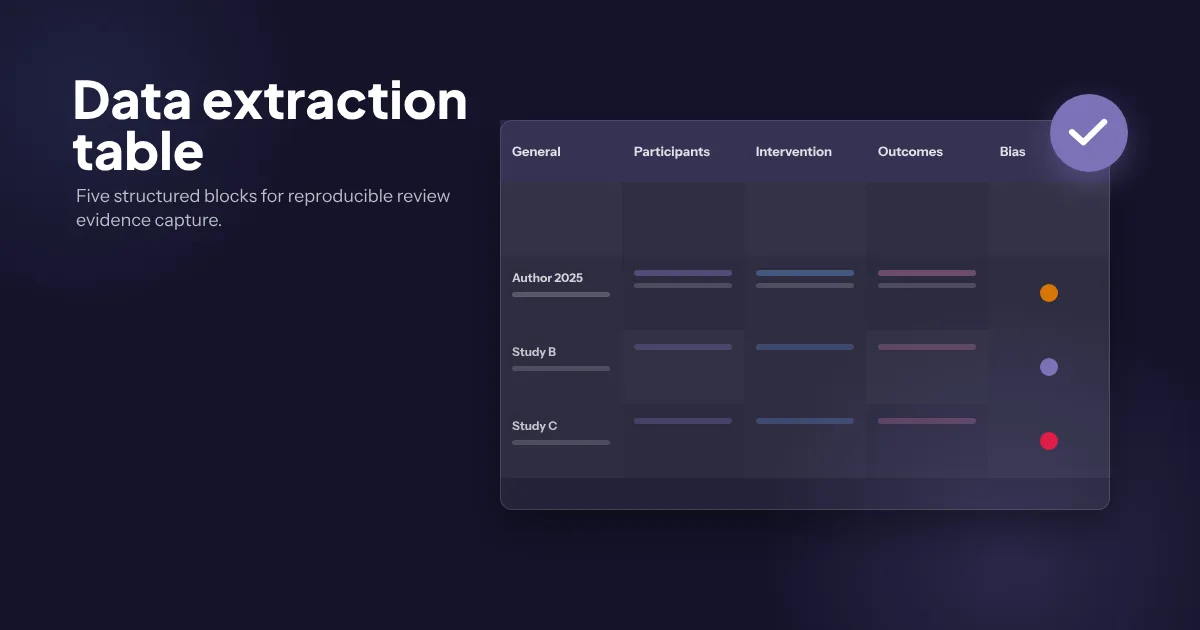
Los cinco bloques de una tabla de extracción
Aunque cada revisión tiene particularidades, una plantilla robusta organiza las variables en cinco bloques. Esta estructura facilita la lectura cruzada entre estudios y simplifica después la construcción de la tabla de características incluidas que aparece en el manuscrito final.
Bloque 1 — Identificación del estudio
Este bloque captura los datos administrativos que permiten localizar y citar cada estudio. Es el bloque más estable entre revisiones porque las variables son siempre las mismas.
| Variable | Descripción | Formato |
|---|---|---|
| ID interno | Código único por estudio en la revisión | Texto corto |
| Primer autor | Apellido del primer autor | Texto |
| Año | Año de publicación | Entero |
| Título | Título completo | Texto |
| Revista | Nombre de la revista | Texto |
| DOI | Identificador digital | Texto |
| País | País donde se realizó el estudio | Texto |
| Idioma original | Idioma de publicación | Texto |
| Fuente de financiación | Quién financió el estudio | Texto |
| Conflicto de interés declarado | Resumen de conflictos reportados | Texto libre |
Bloque 2 — Características de los participantes
Captura las propiedades demográficas y clínicas de la muestra. La operacionalización aquí es crítica: si el criterio de inclusión decía "adultos" y el estudio incluye adolescentes desde 16 años, la decisión de aceptar o rechazar depende de tener bien definidos los umbrales.
| Variable | Descripción | Formato |
|---|---|---|
| Tamaño muestral total | N de la muestra analizada | Entero |
| Tamaño muestral por brazo | N por grupo experimental y control | Entero |
| Edad media | Media en años | Decimal |
| Edad rango | Mínimo y máximo en años | Texto |
| Sexo | Porcentaje de mujeres y hombres | Decimal |
| Condición clínica | Diagnóstico o condición estudiada | Texto |
| Criterios de elegibilidad del estudio | Inclusión y exclusión propias del estudio | Texto libre |
| Contexto | Hospital, comunidad, escuela, online | Texto |
Bloque 3 — Intervención y comparación
Este bloque varía mucho según el tipo de revisión. En revisiones de eficacia de intervenciones farmacológicas captura dosis, vía de administración y duración. En revisiones de intervenciones psicosociales captura formato (individual, grupal), número de sesiones, profesional que lo administra y modalidad (presencial, virtual). En revisiones de exposiciones ambientales captura el tipo de exposición, intensidad y tiempo de seguimiento.
Para revisiones que aspiran a hacer meta-análisis, la operacionalización detallada de este bloque es lo que permite después analizar subgrupos y heterogeneidad. Conviene preparar este bloque junto con el diseño de criterios de inclusión y exclusión, porque ambos comparten la misma lógica de operacionalización.
Bloque 4 — Outcomes
Los outcomes son la razón de ser de la revisión y, paradójicamente, la fuente más frecuente de errores en la extracción. Tres pautas reducen los problemas más comunes.
Primero, distinguir outcomes primarios y secundarios desde el protocolo. Capturar todos los outcomes reportados por cada estudio, no solo los que coinciden con el outcome primario de la revisión. Esto permite analizar después el sesgo de reporte selectivo.
Segundo, capturar el outcome en la unidad y formato originales del estudio. Las transformaciones (cambio de unidad, conversión de mediana a media, derivación de OR desde RR) se hacen después en una columna de análisis, no durante la extracción. La extracción debe preservar el dato tal como lo reportó el estudio para que sea verificable.
Tercero, registrar siempre el momento del outcome. "Reducción del dolor" no es un dato extraíble: "reducción del dolor a las 4 semanas medida con escala VAS de 0 a 10" sí lo es.
| Variable | Descripción | Formato |
|---|---|---|
| Nombre del outcome | Como aparece en el estudio | Texto |
| Tipo | Primario o secundario en el estudio | Texto |
| Instrumento de medida | Escala, cuestionario, biomarcador | Texto |
| Momento de medida | Tiempo desde basal | Texto |
| Valor en grupo experimental | Media DE, mediana RI, eventos N | Texto |
| Valor en grupo control | Media DE, mediana RI, eventos N | Texto |
| Efecto reportado | RR, OR, MD, SMD con IC 95 por ciento | Texto |
| Valor p | Si reportado | Decimal |
Bloque 5 — Riesgo de sesgo
Este bloque captura la evaluación del riesgo de sesgo. La herramienta concreta depende del diseño del estudio: RoB 2 para ensayos clínicos aleatorizados, ROBINS-I para estudios no aleatorizados, JBI critical appraisal tools para diseños cualitativos. Cada dominio se registra como bajo, alto o algún riesgo, con un comentario justificativo.
Plantillas por tipo de estudio
Cinco diseños de estudio cubren la mayoría de las revisiones sistemáticas en salud y ciencias sociales. Cada uno tiene énfasis específicos.
Ensayos clínicos aleatorizados
En ECA, la plantilla debe capturar con detalle el método de aleatorización, ocultamiento de la asignación, cegamiento de participantes, profesionales y evaluadores, manejo de datos faltantes y análisis por intención de tratar versus per protocol. Estos elementos son los dominios principales de RoB 2.
| Bloque específico ECA | Variables clave |
|---|---|
| Diseño | Paralelo, cruzado, factorial |
| Aleatorización | Método de generación de la secuencia |
| Ocultamiento | Asignación al grupo oculta hasta el momento |
| Cegamiento | Participantes, profesionales, evaluadores |
| Pérdidas | Porcentaje de pérdidas por brazo |
| Análisis | ITT, per protocol, ambos |
Estudios de cohorte
En cohortes, el énfasis está en la comparabilidad de los grupos al inicio, el manejo de variables confusoras, la calidad del seguimiento y la definición de los outcomes. La herramienta de evaluación de sesgo recomendada es ROBINS-I o la Newcastle-Ottawa Scale.
| Bloque específico cohorte | Variables clave |
|---|---|
| Tipo | Prospectiva, retrospectiva, mixta |
| Definición de exposición | Cómo se midió y categorizó la exposición |
| Comparabilidad basal | Diferencias entre expuestos y no expuestos |
| Variables confusoras ajustadas | Lista de variables ajustadas en el análisis |
| Duración del seguimiento | Tiempo medio o mediano |
| Pérdidas de seguimiento | Porcentaje y diferencias entre grupos |
Estudios de casos y controles
En casos y controles, el énfasis está en la selección de los controles, la definición operativa del caso, el método de evaluación de la exposición y el control de variables confusoras. La selección de controles es históricamente la fuente más frecuente de sesgo en este diseño.
| Bloque específico caso-control | Variables clave |
|---|---|
| Definición del caso | Criterios diagnósticos |
| Fuente de los casos | Hospitalarios, registro poblacional, otros |
| Selección de controles | Método y emparejamiento |
| Razón casos por controles | 1 a 1, 1 a 2, 1 a 4 |
| Medida de exposición | Cuestionario, registros, biomarcador |
| Sesgo de recuerdo controlado | Sí o no, con justificación |
Estudios transversales
En transversales, las variables clave son la representatividad de la muestra, la tasa de respuesta cuando aplica, los instrumentos de medida validados y los métodos estadísticos usados. El reporte por subgrupos demográficos es esencial para la síntesis posterior.
Estudios cualitativos
En cualitativos, la plantilla cambia de naturaleza. En lugar de capturar datos numéricos, captura el contexto del estudio, el método (etnografía, fenomenología, teoría fundamentada), la técnica de recogida de datos (entrevistas, grupos focales, observación), el análisis (codificación temática, análisis del discurso) y las categorías o temas emergentes. La evaluación de calidad usa herramientas como CASP o JBI cualitativo.
Doble extracción independiente
El estándar metodológico para extracción es que dos revisores extraigan de forma independiente y un tercero reconcilie las discrepancias, o que los dos revisores se reúnan a reconciliar tras comparar sus extracciones. Este proceso es análogo al cribado doble ciego pero aplicado a la fase de extracción, con tres diferencias prácticas relevantes.
Primero, la extracción es más lenta. Donde el cribado de un artículo toma uno a dos minutos por revisor, la extracción puede tomar 30 a 60 minutos por estudio. Esto hace que la doble extracción duplique un coste que ya es alto. Por eso algunos equipos optan por una variante: un revisor extrae todo, el segundo verifica un porcentaje (típicamente 20 a 30 por ciento) y reconcilian. Esta variante es aceptable si la concordancia inicial es alta.
Segundo, las discrepancias en extracción son más variadas que en cribado. En cribado, la discrepancia es binaria: incluir o excluir. En extracción, puede haber diferencias en interpretación de un dato ambiguo, en la unidad reportada, en la clasificación de una variable categórica o en el cálculo derivado. Esto exige un protocolo de reconciliación más estructurado.
Tercero, la reconciliación produce a menudo el descubrimiento de variables mal operacionalizadas que requieren actualizar el manual de codificación y reextraer estudios previos. Es importante registrar estas actualizaciones como enmiendas al protocolo.
Cómo gestionar la reconciliación
La reconciliación efectiva sigue cuatro pasos. Primero, comparar las dos extracciones celda por celda y marcar las celdas con discrepancia. Segundo, para cada discrepancia, los revisores discuten brevemente y resuelven, registrando la decisión en una columna de comentarios. Tercero, las discrepancias no resueltas se elevan a un tercer revisor o al líder metodológico. Cuarto, los cambios al manual de codificación derivados de las discusiones se documentan como enmiendas al protocolo.
Errores típicos en extracción y cómo evitarlos
Cinco errores explican la mayoría de los problemas que aparecen en la fase de análisis cuando la extracción ya está cerrada.
No operacionalizar antes de empezar
Una variable como "intensidad de la intervención" no es extraíble. Una variable como "número de sesiones, duración media de cada sesión en minutos y frecuencia semanal" sí lo es. La operacionalización detallada se hace antes de la primera extracción, no después. El pilotaje con tres a cinco estudios suele revelar las variables mal definidas.
No pilotar la plantilla
El pilotaje consiste en extraer tres a cinco estudios variados con la plantilla diseñada, compartir las extracciones entre los revisores y discutir qué funcionó y qué no. Este pilotaje rara vez toma menos de una jornada completa, pero ahorra semanas de trabajo posterior. Los equipos que saltan esta fase pagan el precio en discrepancias recurrentes durante la extracción real.
No registrar los datos faltantes
Cuando un estudio no reporta un dato, la celda no debe quedar vacía. Quedar vacía hace imposible distinguir después si el dato falta porque el estudio no lo reportó, porque el revisor lo olvidó o porque no aplica. La convención es usar tres códigos: NR (no reportado), NA (no aplica) y nd (no disponible aunque buscado). Esta distinción cambia el análisis: los datos NR pueden ser objeto de contacto con autores, los NA se excluyen del análisis y los nd se reportan como limitación.
No capturar el dato en su unidad original
Convertir unidades durante la extracción es fuente frecuente de errores. La regla es capturar tal como el estudio lo reporta y dejar las transformaciones para una columna de análisis posterior, claramente etiquetada como derivada. Esto preserva la verificabilidad: cualquier auditor externo puede comprobar la celda extraída contra el texto del estudio sin tener que reconstruir cálculos.
No registrar las decisiones interpretativas
Cuando el revisor toma una decisión interpretativa sobre un dato ambiguo, la decisión debe quedar registrada en una columna de comentarios. "El estudio reporta edad como rango 18 a 65; capturado como edad media estimada 41,5 asumiendo distribución uniforme" es un ejemplo de comentario que protege la trazabilidad.
Herramientas disponibles
La elección de la herramienta para gestionar la extracción depende del tamaño del proyecto, el número de revisores y el nivel de estructuración requerido.
Excel y Google Sheets
Para revisiones pequeñas con uno o dos revisores, Excel u Hojas de cálculo de Google son suficientes. La ventaja es que cualquier investigador sabe usarlos. La desventaja es que carecen de validación estructural, no impiden la introducción de datos en formatos inconsistentes y no soportan doble extracción independiente real. Funcionan bien con buena disciplina y un manual de codificación riguroso, peor cuando el equipo es grande o cambia durante el proyecto.
REDCap
REDCap es una plataforma de captura de datos diseñada para investigación clínica que se adapta bien a extracción para revisión sistemática. Permite definir validaciones por campo (rangos numéricos, listas controladas, fechas), genera bitácora de auditoría completa y soporta doble entrada. Es la opción más rigurosa cuando la institución tiene acceso y el equipo está dispuesto a invertir en el diseño del formulario.
RevMan
RevMan, la herramienta de Cochrane, integra la extracción con el análisis posterior. Es la opción natural para revisiones Cochrane formales. La estructura de datos está optimizada para meta-análisis y forest plots. Para revisiones no Cochrane, la curva de aprendizaje puede no compensar.
Plataformas integradas
Plataformas como Covidence, DistillerSR, JBI SUMARI y SynthIA integran extracción, cribado y otras fases del proceso. La ventaja es la continuidad: los estudios ya cribados pasan automáticamente a la fase de extracción sin re-importación. La desventaja es el coste en algunas plataformas y la dependencia de un solo proveedor.
| Herramienta | Adecuada para | Limitación principal |
|---|---|---|
| Excel | Revisiones pequeñas | Sin validación estructural |
| Google Sheets | Equipos pequeños distribuidos | Sin doble entrada real |
| REDCap | Investigación clínica formal | Curva de aprendizaje |
| RevMan | Revisiones Cochrane | Específico al ecosistema Cochrane |
| Covidence | Flujo Cochrane integrado | Precio empresarial |
| SynthIA | Equipos en español | En desarrollo activo |
Pilotaje y manual de codificación
El manual de codificación es el documento que acompaña a la plantilla y define con detalle cómo se codifica cada variable. Cuando dos revisores no están de acuerdo en cómo codificar un dato, la respuesta debe estar en el manual.
Un manual mínimo tiene tres secciones por variable. La definición operativa (qué es exactamente lo que se está midiendo), las opciones válidas (lista controlada de respuestas posibles cuando aplica) y los ejemplos de codificación (al menos dos ejemplos reales de cómo se ha codificado un dato similar previamente).
El pilotaje del manual consiste en aplicar la plantilla y el manual a tres a cinco estudios variados con dos revisores. Comparar las extracciones, identificar las celdas donde hay discrepancias, discutir si la discrepancia se debe a una variable mal definida en el manual o a un error del revisor, actualizar el manual para resolver las ambigüedades reveladas y repetir si es necesario.
Este proceso suele durar una semana para revisiones medianas y es la inversión metodológica de mayor retorno en la fase de extracción.